

Birds Of A Feather? A Comparison Of Google And Captify Cohorts
Written by Raj Gupta, Engineering Manager at Captify, and Veronika Yakymchuk, Machine Learning Engineer at Captify, with thanks to Amelia Waddington, Captify’s VP of Product
Background
In January 2020, Google chrome, the king of browsers, announced they would be deprecating support for third-party cookies by 2022. In its place, they launched the Privacy Sandbox—a collection of proposals to address ad targeting and measurement without third-party cookies. The plan was that the adtech industry as a whole would contribute, collaborate, test, and learn. The first of these proposals to go into the testing phase was FLoC (Federated Learning of Cohorts) in April this year. That trial finished recently and around the same time, Google announced that the ‘cookie depreciation deadline’ would be extended. In this post, we present what we learned about Google’s cohorts, compare them with Captify’s cohorts and offer some views as to why the test was inconclusive.
The idea behind FLoC was to create interest groups to replace third-party cookies as a privacy-first, less intrusive way of targeting ads. Instead of targeting individuals, advertisers would only be able to target groups (“cohorts”) of people sharing similar browsing habits. Google produced a whitepaper outlining how these cohorts would be generated and privacy safeguarding mechanisms. In Google’s initial testing as outlined in the whitepaper, the performance of cohort-based targeting compared favorably to cookie-based targeting, suggesting that the privacy-utility tradeoff was a win-win for both advertisers and users. Some players in the adtech ecosystem have agreed.
Captify Cohorts
Captify is one of the largest independent holders of search data from the open internet—we ingest around 35 billion searches per month. We create groups of users for targeting based on our search data and have done so for many years. We infer intent, interests, and life moments from the searches people make.
Anecdotal evidence suggests that a disproportionately high number of users with FLoC IDs exhibit ‘atypical’ browsing behavior. We do not have the volume to verify this. What we can do is compare FLoC profiles with our internal cohorts that we use for targeting—how similar are they in representing user interests and how stable is their behavior over time?
Stability
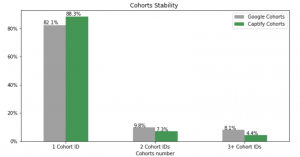
Over a two-month period, we saw that 82% of users in our sample maintained the same FLoC ID as compared to 88% for Captify profiles. It would appear that Google’s algorithm maintains the consistency of user interests that we see in our data, which is important for targeting.
Alignment with Advertiser’s Target Audience
We tried to understand the relationship between Captify profiles and FLoC IDs. Google has not published definitions for their cohorts—we tried mapping the IDs to our internal taxonomies. Figures 2 and 3 below show the distribution of two common Captify segments “Fashionista” and “B2B Technology”.
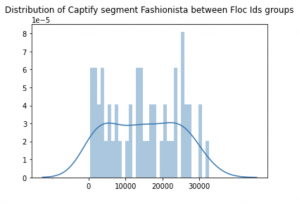
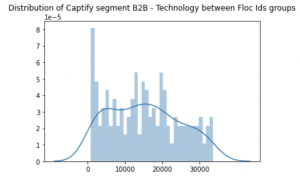
As can be seen, it is difficult to separate dominant Floc IDs for the two segments. The main reason is sample size—the volume of ID-tagged searches ingested was too small (the origin trial only ran on 0.5% of browsers).
It is typical for advertisers working with Captify to pick one or more segments that reflect the hypothesized target audience. Once a campaign is live, the advertiser can optimize the segments that are performing better. As FlocIDs are unlabelled, it would be difficult for advertisers to choose Floc-based audience strategies pre-campaign—including Floc within strategies would have to involve in-campaign optimization. Hence, per the current design, it would be difficult for advertisers to create Floc-based segments.
Privacy
FLoC is one of the pillars in the mission to “create a thriving web ecosystem that is respectful of users and private by default.” (italics ours). This makes the fact that consent is opt-out rather than opt-in somewhat puzzling—and probably motivated Google’s decision not to run the trial in the EU or the UK owing to GDPR-related complications. This will need to be addressed in any further trials.
Conclusion
In conclusion, we found similar levels of stability in user-interests between Google and Captify cohorts. However, owing to an inadequate volume of data, we were unable to map the FLoC IDs to Captify cohorts in a meaningful way. That could change when the new version of the algorithm is introduced and we’re able to ingest enough data. It’s quite likely that the new version will also address the privacy issues raised by GDPR and its equivalents in various countries around the world. However, in the meantime, Captify is steaming ahead with its contextual and search-based “cookie-less” solution which does not depend on any of Google’s proposals. More on that in an upcoming post…


